

八卦,似乎一直是人類茶餘飯後的一個永恆的話題,怎麼辨別一個人與另一個人的關係? 比如是好朋友還是好基友?
但是,這一切私密的問題,AI已經能夠做到精確識別了,這也著實引起了一波恐慌。 就在此前,斯坦福大學兩名研究人員開發了一個神經網絡,可以通過研究一個面部圖像來檢測一個人的性取向。
研究人員訓練了超過35,000張面部圖像的神經網絡,在同性戀和異性戀之間平均分配。 該算法的追踪涉及了遺傳或激素相關的特徵。
這項研究的關鍵在於影響性取向的產前激素理論。 這個理論具體講的是,在子宮中,對性分化負責的主要是雄性激素,也是以後生活中同性戀取向的主要驅動力。 研究還指出,這些特定的雄性激素會在一定程度上影響面部的關鍵特徵,這意味著某些面部特徵可能與性取向有關。
研究發現,男女同性戀傾向於具有“非典型性別特徵”,也就是說男同性戀通常趨向於女性化,而女同性戀反之亦然。 此外,研究人員發現男同性戀通常擁有比直男更窄的下巴、更長的鼻子以及更大的前額,而女同性戀會擁有更大的下巴和更小的前額。

隨機選擇一對圖像,一名同性戀男子和一名異性戀男子,機器挑選受試者的性取向準確率高達80%。 而當與同一人的五張圖像同時呈現對比時,精確度高達91%。 不過,對於女性而言,預測準確率相對較低,一幅圖像準確率為71%,有5幅圖像,則上升至83%。
這一切都讓人們感到了恐懼,AI識別人類性取向,無疑是涉及到了隱私部分,這確實是讓人有所畏懼。 而存儲在社交網絡和政府數據庫中的數十億公共數據將有可能在未獲得本人許可的情況下被用來進行性取向識別,這也是有待商榷的。
除了識別性取向,還可以辨別人物關係
但是,這類型的研究還在繼續。 中山大學的一個團隊可以通過數據集來識別人物關係。 比如是這樣:
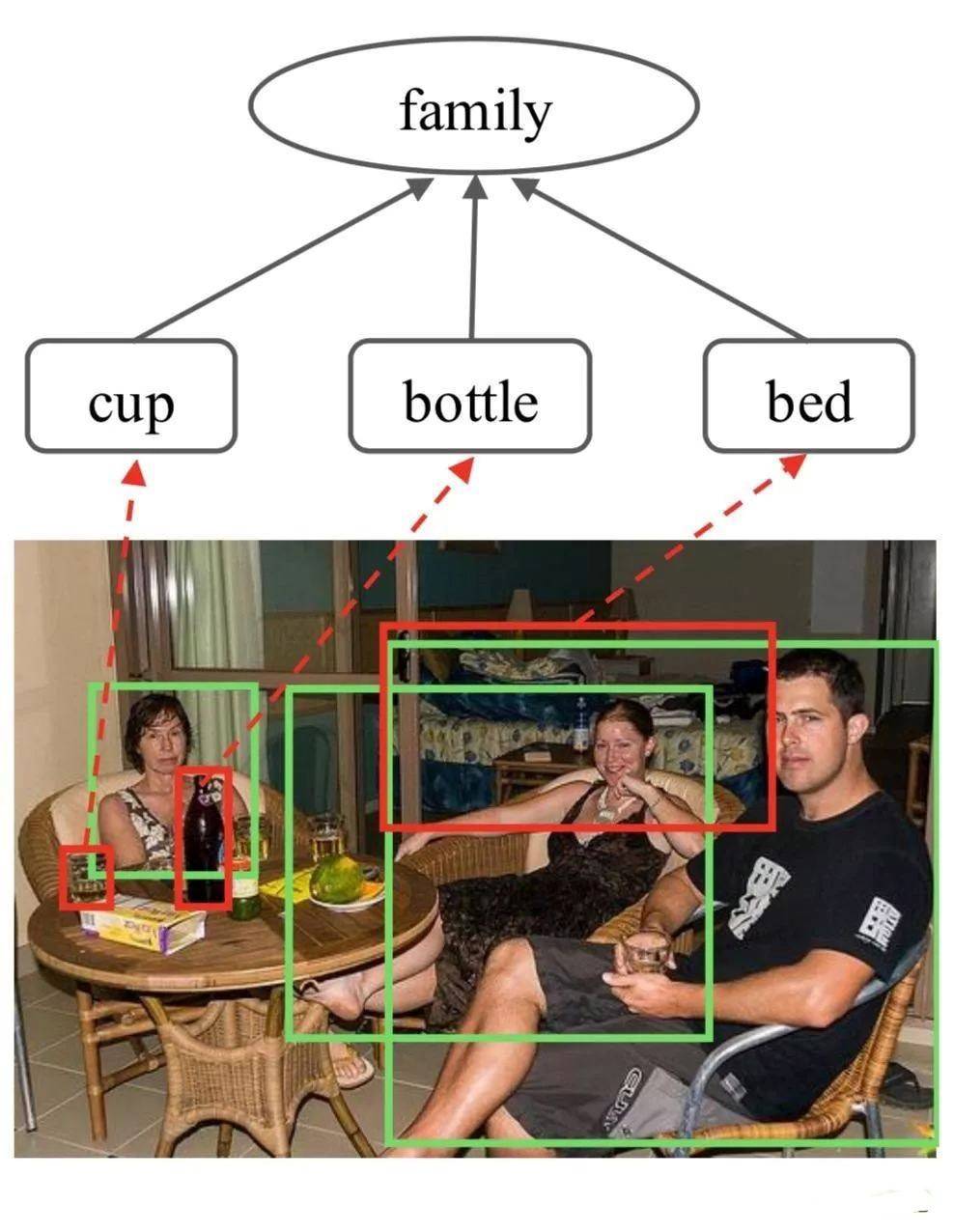
又或者是這樣:
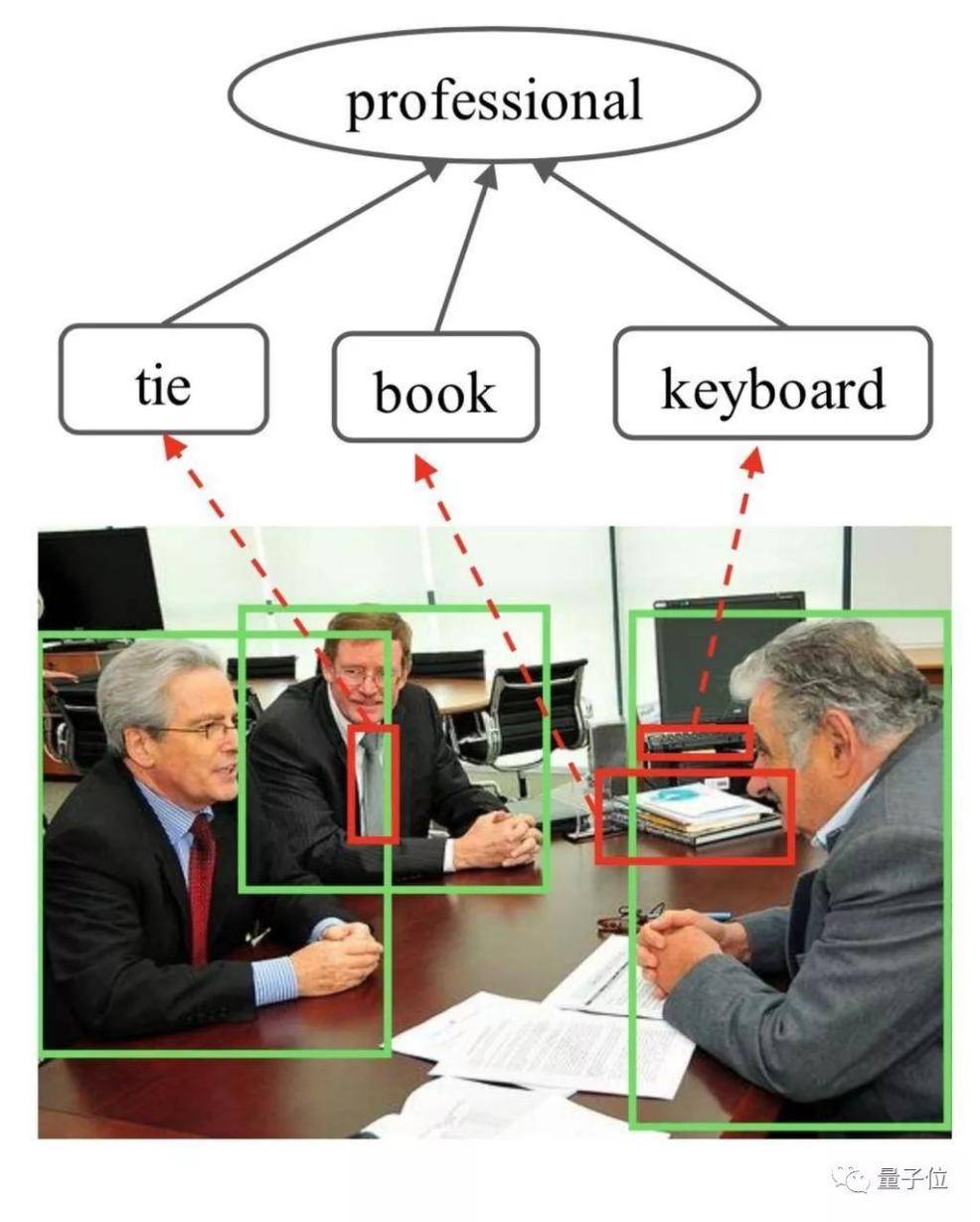
而這一切,基於研究者們訓練了的圖推理模型,由該模型結合門控圖神經網絡對社會關係進行處理。
基於此,AI能夠識別圖片中三者之間的關係,根據圖上人物區域的特徵來初始化關係節點,然後用預先訓練的Faster-RCNN探測器搜索圖像中的語義對象,並提取其特徵,初始化 相應的對象節點;通過圖傳播節點消息以充分探索人與上下文對象的交互,並採用圖注意機制自適應地選擇信息量最大的節點,以通過測量每個對象節點的重要性來促進識別。
但是,在實際表現中,AI識別並未盡如人意。 如警方在歐冠決賽採用AI面部識別匹配潛在犯罪圖像,其錯誤率高達92%,而在人物關係和性取向識別領域,其應用表現也並不優秀。
性取向被識別後,AI倫理的邊界又在哪裡?
《紐約客》曾有這樣一期封面:機器人已經成為了地球的主角,人類只能蹲在地上接受機器人的施捨。 每一個新技術都會引發大家的擔心,但以往更多是人的體力的延伸,而如若是腦力的延伸、人類隱私的延伸,這種擔憂將會更加嚴重。 智能相對論分析師柯鳴認為,性取向識別前,AI還需要解決倫理上的幾大問題。
1.僅靠面部識別太草率
《人格與社會心理學》雜誌曾對斯坦福的這個研究,指出深層神經網絡比人類在通過圖像檢測性取向判斷中更準確,研究涉及建立一種計算機模型,以識別研究人員將其稱作為同性戀者 的“非典型”特徵。
在摘要中,研究人員寫道,“我們認為人們的臉部特徵包涵了更多人腦所無法判斷的性取向特徵。根據一張圖片,系統可以以81%的準確率區分男性同性戀者,74 %的準確率區分女性同性戀者,這比人腦可以完成的判斷準確率都要高。”
但是,在距離應用過程中,僅以面部構造識別似乎並沒有那麼“靠譜”。 技術無法識別人們的性取向,所謂的技術未來只是識別出網絡中同性戀者頭像存在相似的某種模式。
而且,此研究存在的一個問題在於,研究的機制是通過兩張圖片二選一其中最讓機器覺得“更可能是同性戀”的照片,這種對比判斷其實是從50% 的隨機機率開始計算的 ,因此與單純對一張圖的分析有著很大的區別。
這其實就造成了一個問題,在真正人類識別的時候,其準確率有多少,而這種非此即彼的識別方式,其評判標準仍有許多地方需要商榷。
2.算法歧視依然是個“大問題”
算法歧視,一直是人工智能應用過程中的一大問題,以搜索為例,在谷歌上搜索“CEO”,搜索結果中沒有一個是女性,也沒有一個是亞洲人,這是一種潛在的偏見 。
顯然,人工智能也並不是真的純“人工”。 機器學習的方式和人類學習一樣,從文化中提取並吸收社會結構的常態,因此其也會再建、擴大並且延續我們人類為它們設下的道路,而這些道路,一直都將反映現存的社會常態 。
而無論是根據面容來判斷一個人是否誠實,或是判斷他的性取向,這些算法都是基於社會原有生物本質主義,這是一種深信人的性取向等本質是根植於人身體的理論 。 畢竟,一個AI工具通過數據積累和算法模型可以通過照片判斷一個人的性取向,系統準確率高達91%,這其中所帶來的性取向偏見是不能低估的。
今年年初,來自巴斯大學和普林斯頓大學的計算機科學家就曾用類似IAT的聯想類測試來檢測算法的潛在傾向性,並發現即使算法也會對種族和性別帶有偏見。 甚至,連Google 翻譯也難逃偏見,算法“發現”並“學習”了社會約定俗成的偏見。 當在特定語言環境中,一些原本是中性的名詞,如果上下文具有特定形容詞,它會將中性詞轉而翻譯為“他”或“她”。
如今的人工智能還基本局限於完成指定任務,而有時候許多實際應用內容不是非此即彼的,在許多抉擇中,人類選擇依然存在道德困境,如若將決定權交與算法,其存在的詬病 之處更是不言而喻。
3.數據使用,掌握“火候”是關鍵
如果說讓AI野蠻生長是為了解決人們工作效率的問題,那麼當人工智能逐漸落地於各行業後,“體面”已經逐漸取代效率,成為AI應用的關鍵詞。
當然,如果企業能夠全方位的保護用戶隱私,這既有著技術上難度,也缺乏一定商業驅動力,因此,目前來看,如果平衡兩者之間的關係才是關鍵。
實際上,在牽制巨頭破壞用戶隱私方面,歐洲國家已經走得很遠,這體現在這些年他們與Facebook、Google等巨頭對抗的一個個集體訴訟案例中:
2014年8月,Facebook在歐洲遭6萬人起訴,一位奧地利隱私保護人士發起了一項針對Facebook歐洲子公司的大範圍集體訴訟,指控Facebook違背了歐洲數據保護法律,FB被質疑參與了美國 國家安全局的“棱鏡”項目,收集公共互聯網使用的個人數據。
今年1月初,德國政府一家數據保護機構週三表示,該機構已針對Facebook採取法律行動,指控Facebook非法讀取並保存不使用該社交網站的用戶的個人信息。 德國漢堡數據保護辦公室專員表示,由於Facebook在未經許可的情況下收集並保存不使用該社交網站的用戶個人信息,這有可能導致Facebook被罰款數万歐元。
顯然,目前用戶對於自身數據的保護意識正在不斷加強,其在不斷保護自身數據的同時也加強隱私防範。 畢竟,AI識別性取向目前只是研究而沒有落地產品。
而且,從網站上扒圖並不是什麼技術活,讓機器做選擇題的概念,也像極了十多年前哈佛某個宅男做的校園選美網站。 其中滋味,冷暖自知吧。
*文章為作者獨立觀點,不代表虎嗅網立場
本文由 智能相對論 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文章須經作者同意,並請附上出處( 虎嗅網 )及本頁鏈接。 原文鏈接:https://www.huxiu.com/article/254887.html
http://www.buzzfunnews.com/20180726028.html
每日頭條即時更新,請上:http://www.buzzfunnews.com
沒有留言:
張貼留言